


Unicode
This page has been automatically translated using the Google Translate API services. We are working on improving texts. Thank you for your understanding and patience.
Header
#include <sewer/unicode.h>
Functions
| uint32_t | unicode_convers (...) |
| uint32_t | unicode_convers_n (...) |
| uint32_t | unicode_convers_nbytes (...) |
| uint32_t | unicode_convers_nbytes_n (...) |
| uint32_t | unicode_nbytes (...) |
| uint32_t | unicode_nchars (...) |
| uint32_t | unicode_to_u32 (...) |
| uint32_t | unicode_to_u32b (...) |
| uint32_t | unicode_to_char (...) |
| bool_t | unicode_valid_str (...) |
| bool_t | unicode_valid_str_n (...) |
| bool_t | unicode_valid (...) |
| const char_t* | unicode_next (...) |
| const char_t* | unicode_back (...) |
| const char_t* | unicode_move (...) |
| bool_t | unicode_isascii (...) |
| bool_t | unicode_isalnum (...) |
| bool_t | unicode_isalpha (...) |
| bool_t | unicode_iscntrl (...) |
| bool_t | unicode_isdigit (...) |
| bool_t | unicode_isgraph (...) |
| bool_t | unicode_isprint (...) |
| bool_t | unicode_ispunct (...) |
| bool_t | unicode_isspace (...) |
| bool_t | unicode_isxdigit (...) |
| bool_t | unicode_islower (...) |
| bool_t | unicode_isupper (...) |
| uint32_t | unicode_tolower (...) |
| uint32_t | unicode_toupper (...) |
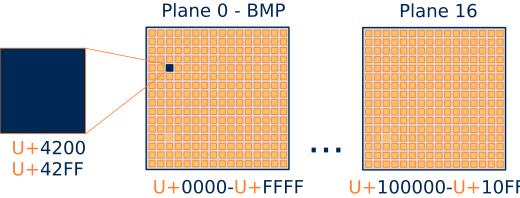
Unicode is a standard in the computer industry, essentially a table, which assigns a unique number to each symbol of each language in the world (Figure 1). These values are usually called codepoints and are represented by typing U+ followed by their number in hexadecimal.
- Use unicode_convers to convert a string from one encoding to another.
- Use unicode_to_u32 to get the first codepoint of a string.

Related to its structure, it has 17 planes of 65536 codepoints each (256 blocks of 256 elements) (Figure 2). This gives Unicode a theoretical limit of 1114112 characters, of which 136755 have already been occupied (version 10.0 of June 2017). For real-world applications, the most important one is Plane 0 called Basic Multilingual Plane (BMP), which includes the symbols of all the modern languages of the world. The upper planes contain historical characters and additional unconventional symbols.
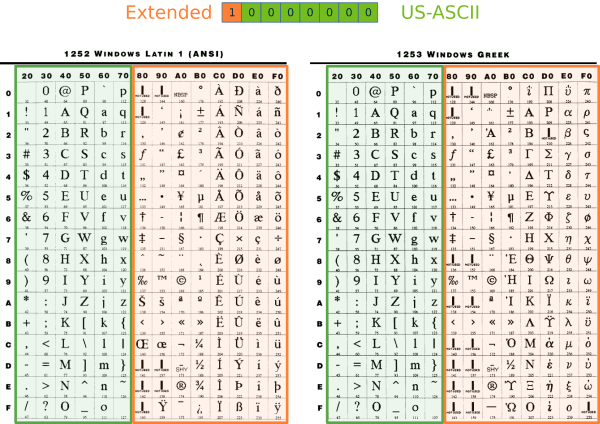
The first computers used ASCII American Standard Code for Information Interchange, a 7-bit code that defines all the characters of the English language: 26 lowercase letters (without diacritics), 26 uppercase letters, 10 digits, 32 punctuation symbols, 33 codes control and a blank space, for a total of 128 positions. Taking the additional bit within a byte, we will have space for another 128 symbols, but still insufficient for all in the world. This results in numerous pages of extended ASCII codes, which is a big problem to share texts, since the same numeric code can represent different symbols according to the ASCII page used (Figure 3).
Already in the early 90s, with the advent of the Internet, this problem worsened, as the exchange of information between machines of different nature and country became something everyday. The Unicode Consortium (Figure 4) was constituted in California in January of 1991 and, in October of the same year, the first volume of the Unicode standard was published.

1. UTF encodings
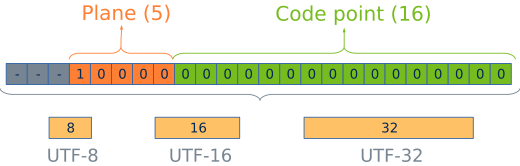
Each codepoint needs 21 bits to be represented (5 for the plane and 16 for the displacement). This match very badly with the basic types in computers (8, 16 or 32 bits). For this reason, three Unicode Translation Format - UTF encodings have been defined, depending on the type of data used in the representation (Figure 5).
1.1. UTF-32
Without any problem, using 32 bits we can store any codepoint. We can also randomly access the elements of an array using an index, in the same way as the classic ASCII C (char) strings. The bad news is the memory requirements. A UTF32 string needs four times more space than an ASCII.
1 2 3 4 5 6 7 8 9 |
1.2. UTF-16
UTF16 halves the space required by UTF32. It is possible to store a codepoint per element as long as we do not leave the 0 plane (BMP). For higher planes, two UTF16 elements (32bits) will be necessary. This mechanism, which encapsulates the higher planes within the BMP, is known as surrogate pairs.
1 2 3 4 5 6 7 8 9 |
To iterate over a UTF16 string that contains characters from any plane, it must be used unicode_next.
1.3. UTF-8
UTF8 is a variable length code where each codepoint uses 1, 2, 3 or 4 bytes.
- 1 byte (0-7F): the 128 symbols of the original ASCII. This is a great advantage, since US-ASCII strings are valid UTF8 strings, without the need for conversion.
- 2 bytes (80-7FF): Diacritical and Romance language characters, Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic, Syriac and Thaana, among others. A total of 1920 codepoints.
- 3 bytes (800-FFFF): Rest of the plane 0 (BMP).
- 4 bytes (10000-10FFFF): Higher planes (1-16).

More than 90% of websites use UTF8 (august of 2018), because it is the most optimal in terms of memory and network transmission speed. As a disadvantage, it has associated a small computational cost to encode/decode, since it is necessary to perform bit-level operations to obtain the codepoints. It is also not possible to randomly access a specific character by index, we have to process the entire string.
1 2 3 4 5 6 7 8 9 10 11 |
const char_t code1[] = "Hello"; const char_t code2[] = "áéíóú"; const char_t *iter = code1; uint32_t s1 = sizeof(code1); /* s1 == 6 */ uint32_t s2 = sizeof(code2); /* s2 == 11 */ for (i = 0; i < 5; ++i) { if (unicode_to_u32(iter, ekUTF8) == 'H') return i; iter = unicode_next(iter, ekUTF8); } |
1.4. Using UTF-8
UTF8 is the encoding required by all the NAppGUI SDK functions. The reasons why we have chosen UTF-8 over other encodings have been:
- It is the natural evolution of the US-ASCII.
- The applications will be directly compatible with the vast majority of Internet services (JSON/XML).
- In multi-lingual environments the texts will occupy less space. Statistically, the 128 ASCII characters are the most used on average and only need one byte in UTF8.
- As a disadvantage, in applications aimed exclusively at the Asian market (China, Japan, Korea - CJK), UTF8 is less efficient than UTF16.
Within NAppGUI applications they can cohexist different representations (char16_t, char32_t, wchar_t). However, we strongly recommend the use of UTF8 in favor of portability and to avoid constant conversions within the API. To convert any string to UTF8 the unicode_convers function is used.
1 2 3 |
wchar_t text[] = L"My label text."; char_t ctext[128]; unicode_convers((const char_t*)text, ctext, ekUTF16, ekUTF8, 128); |
NAppGUI does not offer support for converting pages from Extended ASCII to Unicode.
The Stream object provides automatic UTF conversions when reading or writing to I/O channels using the methods stm_set_write_utf and stm_set_read_utf. It is also possible to work with the String type (dynamic strings), which incorporates a multitude of functions optimized for the UTF8 treatment. We can include constant text strings directly in the source code (Figure 7), although the usual thing will be to write them in resource files (Resources). Obviously, we must save both the source and resource files in UTF8. All current development environments support the option:
- By default, Visual Studio saves the source files in ASCII format (Windows 1252). To change to UTF8, go to
File->Save As->Save with encoding->Unicode (UTF8 Without Signature) - Codepage 65001. There is no way to set this configuration for the entire project :-(. - In Xcode it is possible to establish a global configuration.
Preferences->Text editing->Default Text Encoding->Unicode (UTF-8). - In Eclipse it also allows a global configuration.
Window->Preferences->General->Workspace->Text file encoding.
unicode_convers ()
Converts a Unicode string from one encoding to another.
uint32_t unicode_convers(const char_t *from_str, char_t *to_str, const unicode_t from, const unicode_t to, const uint32_t osize);
1 2 3 |
const char32_t str[] = U"Hello World"; char_t utf8_str[256]; unicode_convers((const char_t*)str, utf8_str, ekUTF32, ekUTF8, 256); |
| from_str | Source string (terminated in null character '\0'). |
| to_str | Destination buffer. |
| from | Source string encoding. |
| to | Coding required in |
| osize | Size of the output buffer. Maximum number of bytes that will be written in |
Return
Number of bytes written in to_str (including the null character).
unicode_convers_n ()
Like unicode_convers, but indicating a maximum size for the input string.
uint32_t unicode_convers_n(const char_t *from_str, char_t *to_str, const unicode_t from, const unicode_t to, const uint32_t isize, const uint32_t osize);
| from_str | Source string. |
| to_str | Destination buffer. |
| from | Source string encoding. |
| to | Coding required in |
| isize | Size of the input string (in bytes). |
| osize | Size of the output buffer. |
Return
Number of bytes written in to_str (including the null character).
unicode_convers_nbytes ()
Gets the number of bytes needed to convert a Unicode string from one encoding to another. It will be useful to calculate the space needed in dynamic memory allocation.
uint32_t unicode_convers_nbytes(const char_t *str, const unicode_t from, const unicode_t to);
1 2 3 |
const char32_t str[] = U"Hello World"; uint32_t size = unicode_convers_nbytes((char_t*)str, ekUTF32, ekUTF8); / * size == 12 * / |
| str | Origin string (null-terminated). |
| from | Encoding of |
| to | Required encoding. |
Return
Number of bytes required (including the null character).
unicode_convers_nbytes_n ()
Same as unicode_convers_nbytes, but indicating the size of the source string.
uint32_t unicode_convers_nbytes_n(const char_t *str, const uint32_t isize, const unicode_t from, const unicode_t to);
| str | Origin string. It is not necessary null-terminated. |
| isize | Size of the input string in bytes. |
| from | Encoding of |
| to | Required encoding. |
Return
Number of bytes required (including the null character).
unicode_nbytes ()
Gets the size (in bytes) of a Unicode string.
uint32_t unicode_nbytes(const char_t *str, const unicode_t format);
| str | Unicode string (null-terminated '\0'). |
| format | Encoding of |
Return
The size in bytes (including the null character).
unicode_nchars ()
Gets the length (in characters) of a Unicode string.
uint32_t unicode_nchars(const char_t *str, const unicode_t format);
| str | Unicode string (null-terminated '\0'). |
| format | Encoding of |
Return
The number of characters ('\0' not included).
Remarks
In ASCII strings, the number of bytes is equal to the number of characters. In Unicode it depends on the coding and the string.
unicode_to_u32 ()
Gets the value of the first codepoint of the Unicode string.
uint32_t unicode_to_u32(const char_t *str, const unicode_t format);
1 2 3 |
char_t str[] = "áéíóúÄÑ£"; uint32_t cp = unicode_to_u32(str, ekUTF8); /* cp == 'á' == 225 == U+E1 */ |
| str | Unicode string (null-terminated '\0'). |
| format | Encoding of |
Return
The code of the first str character.
unicode_to_u32b ()
Like unicode_to_u32 but with an additional field to store the number of bytes occupied by the codepoint.
uint32_t unicode_to_u32b(const char_t *str, const unicode_t format, uint32_t *bytes);
| str | Unicode string (null-terminated '\0'). |
| format | Encoding of |
| bytes | Saves the number of bytes needed to represent the codepoint by |
Return
The code of the first str character.
unicode_to_char ()
Write the codepoint at the beginning of str, using the format encoding.
uint32_t unicode_to_char(const uint32_t codepoint, char_t *str, const unicode_t format);
1 2 3 4 5 |
char_t str[64] = \"\";
uint32_t n = unicode_to_char(0xE1, str, ekUTF8);
unicode_to_char(0, str + n, ekUTF8);
/* str == "á" */
/* n = 2 */
|
| codepoint | Character code. |
| str | Destination string. |
| format | Encoding for |
Return
The number of bytes written (1, 2, 3 or 4).
Remarks
To write several codepoints, combine unicode_to_char with unicode_next.
unicode_valid_str ()
Check if a string is a valid Unicode.
bool_t unicode_valid_str(const char_t *str, const unicode_t format);
| str | String to be checked (ending in '\0'). |
| format | Expected Unicode encoding. |
Return
TRUE if it is valid.
unicode_valid_str_n ()
Like unicode_valid_str, but indicating a maximum size for the input string.
bool_t unicode_valid_str_n(const char_t *str, const uint32_t size, const unicode_t format);
| str | String to be checked (ending in '\0'). |
| size | Maximum size of the string (in bytes). |
| format | Expected Unicode encoding. |
Return
TRUE if it is valid.
unicode_valid ()
Check if a codepoint is valid.
bool_t unicode_valid(const uint32_t codepoint);
| codepoint | The Unicode code of the character. |
Return
TRUE if the parameter is a valid codepoint. FALSE otherwise.
unicode_next ()
Advance to the next character in a Unicode string. In general, random access is not possible as we do in ANSI-C (str[i++]). We must iterate a string from the beginning. More in UTF encodings.
const char_t* unicode_next(const char_t *str, const unicode_t format);
1 2 3 4 5 6 7 8 9 |
char_t str[] = "áéíóúÄ"; char_t *iter = str; /* iter == "áéíóúÄ" */ iter = unicode_next(iter, ekUTF8); /* iter == "éíóúÄ" */ iter = unicode_next(iter, ekUTF8); /* iter == "íóúÄ" */ iter = unicode_next(iter, ekUTF8); /* iter == "óúÄ" */ iter = unicode_next(iter, ekUTF8); /* iter == "úÄ" */ iter = unicode_next(iter, ekUTF8); /* iter == "Ä" */ iter = unicode_next(iter, ekUTF8); /* iter == "" */ iter = unicode_next(iter, ekUTF8); /* Segmentation fault!! */ |
| str | Unicode string. |
| format |
|
Return
Pointer to the next character in the string.
Remarks
It does not verify the end of the string. We must stop the iteration when codepoint == 0.
unicode_back ()
Go back to the previous character of a Unicode string.
const char_t* unicode_back(const char_t *str, const unicode_t format);
| str | Unicode string. |
| format |
|
Return
Pointer to the previous character of the string.
Remarks
It does not verify the beginning of the string.
unicode_move ()
Advances nchars characters from a Unicode string. Equivalent to several calls to unicode_next.
const char_t* unicode_move(const char_t *str, const uint32_t nchars, const unicode_t format);
1 2 3 4 |
char_t str[] = "áéíóúÄ"; char_t *iter = str; /* iter == "áéíóúÄ" */ iter = unicode_move(iter, 4, ekUTF8); /* iter == "úÄ" */ iter = unicode_move(iter, 20, ekUTF8); /* iter == "" */ |
| str | Unicode string. |
| nchars | Number of characters to advance. |
| format |
|
Return
Pointer to the numbered nchars character in the string.
Remarks
If the string has fewer than nchars characters, it will return the null character '\0'. It will not advance beyond the buffer limits.
unicode_isascii ()
Check if codepoint is a US-ASCII 7 character.
bool_t unicode_isascii(const uint32_t codepoint);
| codepoint | The Unicode character code. |
Return
Test result.
unicode_isalnum ()
Check if codepoint is an alphanumeric character.
bool_t unicode_isalnum(const uint32_t codepoint);
| codepoint | The Unicode character code. |
Return
Test result.
Remarks
Only consider US-ASCII characters.
unicode_isalpha ()
Check if codepoint is an alphabetic character.
bool_t unicode_isalpha(const uint32_t codepoint);
| codepoint | The Unicode character code. |
Return
Test result.
Remarks
Only consider US-ASCII characters.
unicode_iscntrl ()
Check if codepoint is a control character.
bool_t unicode_iscntrl(const uint32_t codepoint);
| codepoint | The Unicode character code. |
Return
Test result.
Remarks
Only consider US-ASCII characters.
unicode_isdigit ()
Check if codepoint is digit (0-9).
bool_t unicode_isdigit(const uint32_t codepoint);
| codepoint | The Unicode character code. |
Return
Test result.
Remarks
Only consider US-ASCII characters.
unicode_isgraph ()
Check if codepoint is a printable character (except white space ' ').
bool_t unicode_isgraph(const uint32_t codepoint);
| codepoint | The Unicode character code. |
Return
Test result.
Remarks
Only consider US-ASCII characters.
unicode_isprint ()
Check if codepoint is a printable character (including white space ' ').
bool_t unicode_isprint(const uint32_t codepoint);
| codepoint | The Unicode character code. |
Return
Test result.
Remarks
Only consider US-ASCII characters.
unicode_ispunct ()
Check if codepoint is a printable character (expect white space ' ' and alphanumeric).
bool_t unicode_ispunct(const uint32_t codepoint);
| codepoint | The Unicode character code. |
Return
Test result.
Remarks
Only consider US-ASCII characters.
unicode_isspace ()
Check if codepoint is a spacing character, new line, carriage return, horizontal or vertical tab.
bool_t unicode_isspace(const uint32_t codepoint);
| codepoint | The Unicode character code. |
Return
Test result.
Remarks
Only consider US-ASCII characters.
unicode_isxdigit ()
Check if codepoint is a hexadecimal digit 0 1 2 3 4 5 6 7 8 9 a b c d e f A B C D E F.
bool_t unicode_isxdigit(const uint32_t codepoint);
| codepoint | The Unicode character code. |
Return
Test result.
Remarks
Only consider US-ASCII characters.
unicode_islower ()
Check if codepoint is a lowercase letter.
bool_t unicode_islower(const uint32_t codepoint);
| codepoint | The Unicode character code. |
Return
Test result.
Remarks
Only consider US-ASCII characters.
unicode_isupper ()
Check if codepoint is a capital letter.
bool_t unicode_isupper(const uint32_t codepoint);
| codepoint | The Unicode character code. |
Return
Test result.
Remarks
Only consider US-ASCII characters.
unicode_tolower ()
Convert a letter to lowercase.
uint32_t unicode_tolower(const uint32_t codepoint);
| codepoint | The Unicode character code. |
Return
The conversion to lowercase if the entry is a capital letter. Otherwise, the same codepoint.
Remarks
Only consider US-ASCII characters.
unicode_toupper ()
Convert a letter to uppercase.
uint32_t unicode_toupper(const uint32_t codepoint);
| codepoint | The Unicode character code. |
Return
The conversion to upper case if the entry is a lowercase letter. Otherwise, the same codepoint.
Remarks
Only consider US-ASCII characters.