


Hebras
Las hebras o hilos son partes del mismo programa que pueden correr en paralelo.
Cabecera
#include <osbs/bthread.h>
Funciones
| Thread* | bthread_create (...) |
| int | bthread_current_id (void) |
| void | bthread_close (...) |
| void | bthread_cancel (...) |
| uint32_t | bthread_wait (...) |
| bool_t | bthread_finish (...) |
| void | bthread_sleep (...) |
Los hilos o hebras son diferentes caminos de ejecución dentro del mismo proceso (Figura 1). También son conocidos como procesos ligeros, ya que son más ágiles de crear y gestionar que los procesos propiamente dichos. Comparten código y espacio de memoria con el programa principal, por lo que es muy fácil intercambiar información entre ellos a través de variables de memoria. Una hebra comienza su ejecución en un método conocido como thread_main y, en el momento que se lanza, se ejecuta en paralelo con el hilo principal. Al igual que los procesos, son objetos controlados por el núcleo del sistema que dictaminará, en última instancia, si la hebras se ejecutarán en otro CPU-core (true multitasking) o lo compartirán (context switch).
- Utiliza bthread_create para crear un nuevo hilo de ejecución.
- Utiliza bthread_wait para obligar al hilo principal a que espere que se ejecute el hilo.
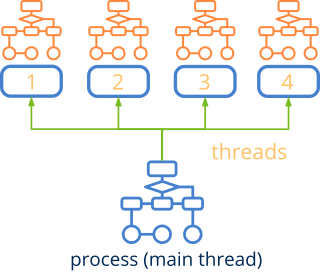
1. Lanzando hebras
Cada llamada a bthread_create creará un nuevo hilo en paralelo comenzando en la función pasada como parámetro (thread_main). La forma "natural" de finalizarlo es retornando de thread_main, aunque es posible abortarlo desde el hilo principal.
1 2 3 4 5 6 7 8 9 10 11 |
static uint32_t i_thread(ThData *data) { // Do something ... // Thread execution ends return 0; } Thread *thread = bthread_create(i_thread, data, ThData); // Main thread will continue here // Second thread will run 'i_thread' |
2. Variables compartidas
Cada nuevo hilo tiene su propio Segmento Stack por tanto, todas las variables automáticas, llamadas a función y reservas dinámicas serán privadas a dicho hilo. Pero también puede recibir datos globales del proceso a través del parámetro data de thread_main. Debemos tener cuidado al acceder a datos globales a través de múltiples hilos concurrentes, ya que modificaciones realizadas por otros hilos pueden alterar la ejecución lógica del código produciendo errores muy difíciles de depurar. El programa (Listado 1) es correcto para programas de un solo hilo, pero si la variable vector es accedida por dos hebras simultáneas, puede derivar en un error Segmentatin Fault si la hebra-1 libera la memoria mientras la hebra-2 está ejecutando el bucle.
1 2 3 4 5 6 7 8 |
Para evitar este problema, deberemos proteger los accesos a variables compartidas a través de un Mutex (Listado 2). Este mecanismo de Exclusión mutua garantiza que solo un hilo puede acceder al recurso en un instante de tiempo. Un hilo será detenido si pretende ejecutar el código situado entre bmutex_lock y bmutex_unlock si otro hilo se encuentra dentro de esta sección crítica.
1 2 3 4 5 6 7 8 9 10 |
bmutex_lock(shared->mutex); if (shared->vector != NULL) { shared->total = 0; for(i = 0; i < shared->n; i++) shared->total += shared->vector[i]; bmem_free(shared->vector); shared->vector = NULL; } bmutex_unlock(shared->mutex); |
3. Ejemplo multi-hilo
Lo complicado de la programación multi-hilo es descomponer una solución en partes que puedan correr en paralelo y organizar las estructuras de datos para que esto se pueda llevar a cabo de la forma más equilibrada posible. En (Listado 3) el programa correrá cuatro veces más rápido (x4) ya que se ha hecho una división perfecta del problema (Figura 2). Esto no es más que un ejemplo teórico y este resultado será muy difícil de conseguir en situaciones reales. También deberemos reducir al mínimo la cantidad de variables compartidas y el tiempo de las secciones críticas, de lo contrario los posibles inter-bloqueos reducirán la ganancia.
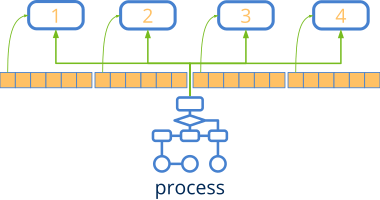
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
typedef struct _app_t App; typedef struct _thdata_t ThData; struct _app_t { uint32_t total; uint32_t n; uint32_t *elems; Mutex *mutex; }; struct _thdata_t { uint32_t thread_id; uint32_t start; uint32_t end; uint64_t time; App *app; }; static uint32_t i_thread(ThData *data) { uint32_t i, total = 0; uint64_t t1 = btime_now(); for (i = data->start; i < data->end; ++i) { // Simulates processing uint32_t time = bmath_randi(0, 100); bthread_sleep(time); total += data->app->elems[i]; } // Mutual exclusion access to shared variable 'total' bmutex_lock(data->app->mutex); data->app->total += total; bmutex_unlock(data->app->mutex); data->time = (btime_now() - t1) / 1000; return data->thread_id; } // Threads creating function uint32_t i, m; uint64_t t; App app; ThData thdata[4]; Thread *thread[4]; // App data vector i_init_data(&app); app.mutex = bmutex_create(); m = app.n / 4; // Thread data for (i = 0; i < 4; ++i) { thdata[i].thread_id = i; thdata[i].app = &app; thdata[i].start = i * m; thdata[i].end = (i + 1) * m; } // Launching threads t = btime_now(); for (i = 0; i < 4; ++i) thread[i] = bthread_create(i_thread, &thdata[i], ThData); // Wait for threads end for (i = 0; i < 4; ++i) { uint32_t thid = bthread_wait(thread[i]); bstd_printf("Thread %d finished in %d ms.\n", thid, thdata[thid].time); bthread_close(&thread[i]); } // Process total time t = (btime_now() - t) / 1000; bstd_printf("Processing result = %d in %d ms.\n", app.total, t); bmutex_close(&app.mutex); |
1 2 3 4 5 |
Thread 0 finished in 13339 ms. Thread 1 finished in 12506 ms. Thread 2 finished in 12521 ms. Thread 3 finished in 12999 ms. Processing result = 499500 in 13344 ms. |
bthread_create ()
Crea un nuevo hilo de ejecución, que arranca en thmain.
Thread* bthread_create(FPtr_thread_main thmain, type *data, type);
| thmain | La función de inicio de la hebra thread_main. Se pueden pasar datos compartidos mediante el puntero data. |
| data | Datos pasados como parámetro a |
| type | Tipo de |
Retorna
Manejador de la hebra. Si la función falla, retorna NULL.
Observaciones
El hilo se ejecutará en paralelo hasta que thmain retorne o se llame a bthread_cancel. Lanzando hebras.
bthread_current_id ()
Retorna el identificador manejador de la hebra actual, es decir, la que está corriendo cuando se llama a esta función.
int bthread_current_id(void);
Retorna
Manejador de la hebra.
bthread_close ()
Cierra el manejador de la hebra y libera recursos.
void bthread_close(Thread **thread);
| thread | Manejador de la hebra. Será puesto a |
Observaciones
Si el hilo todavía se está ejecutando, esta función no lo finaliza. Como cualquier otro objeto, un hilo siempre debe cerrarse, incluso si ya ha terminado su ejecución. Lanzando hebras.
bthread_cancel ()
Fuerza la terminación del hilo especificado.
void bthread_cancel(Thread *thread);
| thread | Manejador de la hebra. |
Observaciones
No es recomendable llamar a esta función. No se realizará una salida "limpia" del hilo. Si se encuentra dentro de una sección crítica, esta no será liberada. Tampoco de liberará la memoria dinámica reservada de forma privada por el hilo. La forma correcta de finalizar un hilo de ejecución es retornando de thmain. Pueden utilizarse variables compartidas (Exclusión mutua) para indicarle a un hilo que debe terminar de forma limpia.
bthread_wait ()
Detiene al hilo que llama a esta función hasta que thread termina su ejecución.
uint32_t bthread_wait(Thread *thread);
| thread | Manejador de la hebra a la que debemos esperar. |
Retorna
El valor de retorno del hilo. Si ocurre algún error, retorna UINT32_MAX.
bthread_finish ()
Comprueba si la hebra sigue en ejecución.
bool_t bthread_finish(Thread *thread, uint32_t *code);
| thread | Manejador de la hebra. |
| code | El valor de retorno de la función thmain (si ha terminado). Puede ser |
Retorna
TRUE si el hilo ha terminado, FALSE si no.
Observaciones
Esta función retorna inmediatamente.
bthread_sleep ()
Suspende la ejecución de la hebra actual (la que llama a esta función) durante un número determinado de milisegundos.
void bthread_sleep(const uint32_t milliseconds);
| milliseconds | Intervalo de tiempo (en milisegundos) que durará la suspensión. |
Observaciones
Realiza una suspensión "pasiva", donde ningún "bucle vacío" será ejecutado. El hilo es decartado por el scheduler y reactivado posteriormente.