


Error management
This page has been automatically translated using the Google Translate API services. We are working on improving texts. Thank you for your understanding and patience.
There is always one more bug to fix. Ellen Ullman
Developing software of a certain size and complexity can become a hellish task, if we do not adopt concrete measures to prevent and quickly locate programming bugs. Next we will talk about some strategies that we have used in the development of NAppGUI and that you can apply in your own projects.
1. Exhaustive tests
Ensuring that our software is bug free is as "easy" as running a test for each and every case the (Figure 1) program will face.
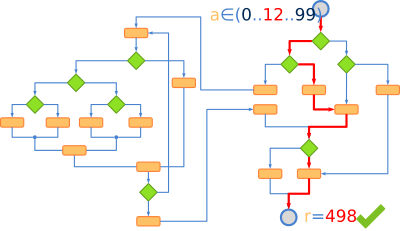
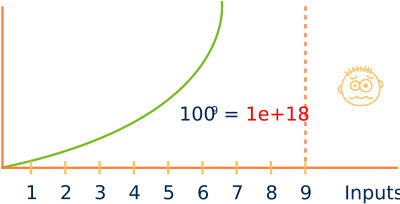
Already from trivial theoretical examples, we see that we are dealing with an exponential problem (Figure 2), which will overwhelm the resources of any system with relatively few input variables. Therefore, we can intuit that it will be impossible to guarantee that our software is free of errors since it will not be feasible to reproduce all its use cases. However, we can define a strategy that helps us minimize the impact that these will have on the final product, detecting and correcting them as soon as possible.
2. Static analysis
Static analysis is the one that is carried out before executing the program and consists of two parts: The use of standards where rules and quality controls are applied during the writing of the code itself. And the compiler warnings that will help us locate potential compile-time errors.
2.1. Standards
The use of standards, understood as rules that we follow when programming, is essential when it comes to maintaining minimum levels of quality in our (Figure 3) projects. If they are not applied, a program of a certain size will become anarchic, unreadable, difficult to maintain and difficult to understand. In this scenario it will be easy to add new bugs as we manipulate the source code.

In reality, it is difficult to differentiate between good and bad standards, since they will depend on the type of project, programming languages, company philosophy and objectives to prioritize. We can see them as a Style Guide that evolves over time hand in hand with experience. What is truly important is to become aware of their usefulness, define and apply them. For example, if we decide to name variables with descriptive identifiers in English and an underscore (product_code), all our code should follow this rule without exception. Let's take a look at some of the standards we apply within NAppGUI. They are not the best nor do they have to adapt to all cases. They are only ours:
- Use a small subset of the language, as we've seen in Use of C. For example, expressions of the type
*((int*)block + i++) = i+1, are totally prohibited. They are perfectly valid in C but poorly readable and confusing. Some programmers think that cryptic and compact code is much more maintainable, but we think they are wrong. - Comments are prohibited, except on rare occasions and very justified. If something needs a comment, rewrite it. A comment that even slightly contradicts the code it is intended to clarify causes more confusion than help. And it is very easy for them to become obsolete.
- Reduced and clean public interfaces. Header files (
*.h) represent a high level of abstraction as they reduce the connections between software components (Figure 4). They allow condensing, as an index, hundreds or thousands of lines of code in just fifteen or twenty public functions. It is completely forbidden to include type definitions (they will go in the*.hxx), comments (of course) and documentation blocks in.hfiles. - Opaque objects. Object definitions (
struct _object_t) will be made inside the implementation files (*.c) and never in the*.h. The objects will be manipulated with public functions that accept pointers to them, always hiding the fields that compose them. This point, together with the previous one on interfaces, perfectly defines the barriers between modules, clearly marking when one problem ends and another begins.
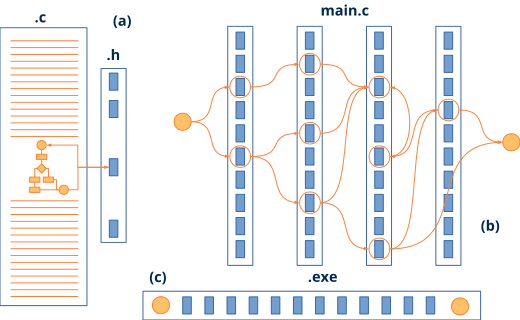
*.h headers provide a high level of abstraction hiding the complexity of the (a) solution. They facilitate horizontal, problem-based development, as opposed to vertical learning based on (b) APIs. They help the linker reduce the size of the (c) executable.The first two rules help reduce the internal complexity of a module by making it as readable and less cryptic as possible. We could enrich them with others about indentation, style, variable naming, etc. We more or less strictly follow the advice of the great book The Practice of Programming (Figure 5).

2.2. Compiler warnings
The compiler is our great ally when it comes to examining the code for possible (Figure 6) errors. Enabling the highest possible level of warnings is essential to reduce errors caused by type conversions, uninitialized variables, unreachable code, etc. All projects built with NAppGUI will trigger the highest level of warnings possible, equivalent to -Wall -Wpedantic on all (Figure 7) platforms.
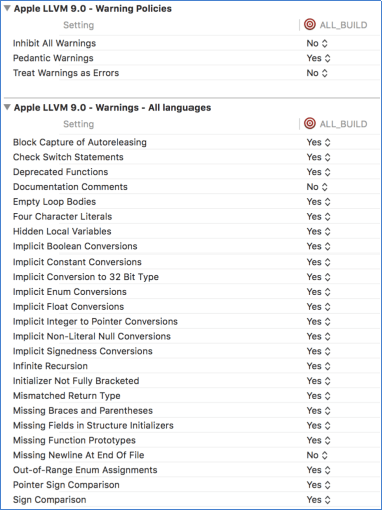
3. Dynamic analysis
Dynamic analysis is performed once the program is running. Here our main weapon is self-validations, implemented as Asserts statements. Asserts are checks distributed throughout the source code, which are evaluated at runtime each time the program goes through them. If a statement resolves to FALSE, processing will stop and an (Figure 8) informational window will be displayed.
1 2 3 4 5 6 |
void layout_set_row_margin(Layout *layout, const uint32_t row, const real32_t margin) { cassert_no_null(layout); cassert_msg(row < layout->num_rows, "'row' out of range"); ... } |
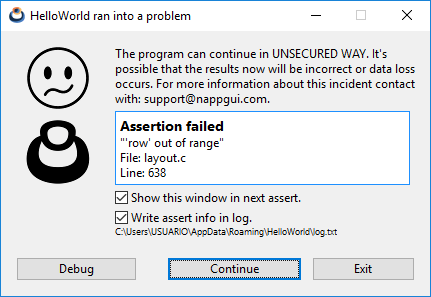
It is also possible to redirect assert statements to standard output or to the Log file.
3.1. Disabling Asserts
Within the NAppGUI SDK code, more than 5000 assertions have been distributed, located at strategic points, which constantly evaluate the coherence and integrity of the software. Obviously, this number will grow after each revision, as more functionality is integrated. This turns the SDK into a real minefield, where any error in the use of the API functions will be automatically notified to the programmer. Depending on the configuration we are using, the assertions will be activated or deactivated:
Debug: Assert statements are enabled.Release: The sentences assert are disabled.ReleaseWithDebInfo: As the name suggests, turns on all Release optimizations, but leaves assert statements on.
3.2. Debugging the program
When an assert is activated, the program stops right at the check point, showing the assert confirmation window. If we press the [Debug] button, we will access the call stack (Figure 9), which is the current function call stack, from the main() itself to the current breakpoint Stack Segment. By browsing the stack we can check the values of variables and objects at any call level. This will help us identify the source of the error, as the cause may be a few levels below detection.
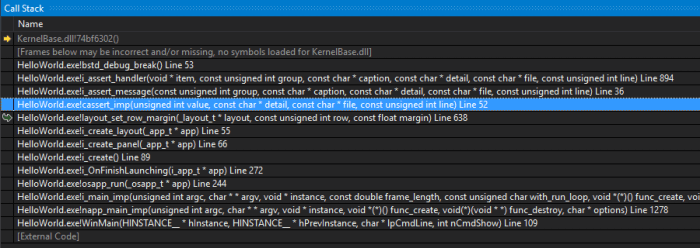
3.3. Error log
An execution Log is a file where the program dumps information about its status or anomalies detected. It can be very useful to know the cause of a failure when the software has already been distributed and it is not possible to debug it. NAppGUI automatically creates a log file for each application located in the application data directory APP_DATA\APP_NAME\log.txt, for example C:\Users\USER\AppData\Roaming\ HelloWorld\log.txt.
1 2 3 4 5 |
[15:42:29] Starting log for 'HelloWorld' [15:42:29] TextView created: [0x6FFC7A30] [15:42:32] Assertion failed (c:\\nappgui_1_0\\src\\gui\\layout.c:638): "'row' out of range" [15:42:32] Assertion failed (c:\\nappgui_1_0\\src\\core\\array.c:512): "Array invalid index" [15:42:34] You have an execution log in: 'C:\\Users\\USUARIO\\AppData\\Roaming\\HelloWorld\\log.txt' |
As you can see, the assertions are automatically redirected to the log file. It is possible to disable this writing by unchecking the 'Write assert info in log' check in the info window. You can also add your own messages using the log_printf method.
1 |
log_printf("TextView created: [0x%X]", view);
|
3.4. Memory auditor
NAppGUI's memory manager Heap has an associated auditor that checks for leaks memory after each execution of each application that uses the SDK. This is a great advantage over using external utilities, as dynamic memory checks are being performed always and not in isolated phases of development.
1 2 3 4 5 6 7 8 9 10 11 |
[18:57:33] [OK] Heap Memory Staticstics [18:57:33] ============================ [18:57:33] Total a/dellocations: 652962, 652962 [18:57:33] Total bytes a/dellocated: 18085221250, 18085221250 [18:57:33] Max bytes allocated: 238229150 [18:57:33] Effective reallocations: (0/1169761) [18:57:33] Real allocations: 32776 pages of 65536 bytes [18:57:33] 13271 pages greater than 65536 bytes [18:57:33] ============================ [18:57:33] Config: Debug [18:57:33] You have an execution log in: 'C:\Users\USUARIO\AppData\Roaming\EuroPlane\log.txt'code. |