


Gestión de errores
Siempre hay un error más que arreglar. Ellen Ullman
Desarrollar software de cierto tamaño y complejidad puede convertirse en una tarea infernal, si no adoptamos medidas concretas para la prevención y rápida localización de los bugs de programación. Hablaremos a continuación de algunas estrategias que hemos utilizado en el desarrollo de NAppGUI y que puedes aplicar en tus propios proyectos.
1. Pruebas exhaustivas
Asegurar que nuestro software está libre de errores es tan "sencillo" como realizar una prueba para todos y cada uno de los casos a los que se va a enfrentar el programa (Figura 1).
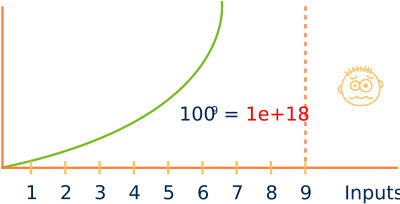
Ya desde ejemplos teóricos triviales, vemos que estamos tratando con un problema exponencial (Figura 2), que desbordará los recursos de cualquier sistema con relativamente pocas variables de entrada. Por tanto, podemos intuir que será imposible garantizar que nuestro software esté libre de errores ya que no será viable reproducir todos sus casos de uso. Sin embargo, podemos definir una estrategia que nos ayude a minimizar el impacto que estos tendrán en el producto final, detectándolos y corrigiéndolos lo antes posible.
2. Análisis estático
El análisis estático es aquel que se lleva a cabo antes de ejecutar el programa y consta de dos partes: El uso de estándares donde se aplican reglas y controles de calidad durante la propia escritura del código. Y los avisos del compilador que nos ayudarán a localizar potenciales errores en tiempo de compilación.
2.1. Estándares
El uso de estándares, entendidos como reglas que seguimos al programar, es algo esencial a la hora de mantener unos niveles mínimos de calidad en nuestros proyectos (Figura 3). De no aplicarlos, un programa de cierto tamaño se tornará anárquico, ilegible, difícil de mantener y complicado de entender. En este escenario será fácil añadir nuevos errores a medida que manipulamos el código fuente.

En realidad, es complicado diferenciar entre buenos y malos estándares, ya que dependerán del tipo de proyecto, lenguajes de programación, filosofía de la empresa y objetivos a priorizar. Podemos verlos como una Guía de Estilo que va evolucionando con el tiempo de la mano de la experiencia. Lo verdaderamente importante es concienciarnos de su utilidad, definirlos y aplicarlos. Por ejemplo, si decidimos nombrar variables con identificadores descriptivos en Inglés y guión bajo (product_code), todo nuestro código debería cumplir esta regla sin excepción. Vamos a ver algunos de los estándares que aplicamos dentro de NAppGUI. No son los mejores ni tienen porque adaptarse a todos los casos. Tan solo son los nuestros:
- Utilizar un subconjunto reducido del lenguaje, como hemos visto en Uso de C. Por ejemplo, expresiones del tipo
*((int*)block + i++) = i+1, están totalmente prohibidas. Son perfectamente válidas en C pero poco legibles y confusas. Algunos programadores piensan que el código críptico y compacto es mucho más mantenible, pero creemos que están equivocados. - Prohibidos los comentarios, salvo en contadas ocasiones y muy justificadas. Si algo precisa de un comentario, reescríbelo. Un comentario que contradiga mínimamente al código que pretende clarificar produce más confusión que ayuda. Y es muy sencillo que queden obsoletos.
- Interfaces públicas reducidas y limpias. Los ficheros de cabecera (
*.h) suponen un gran nivel de abstracción ya que reducen las conexiones entre componentes software (Figura 4). Permiten condensar, a modo de índice, cientos o miles de líneas de código en apenas quince o veinte funciones públicas. Está completamente prohibido incluir definiciones de tipos (irán en el*.hxx), comentarios (por supuesto) y bloques de documentación en archivos.h. - Objetos opacos. Las definiciones de objetos (
struct _object_t) se realizarán dentro de los ficheros de implementación (*.c) y nunca en el*.h. Los objetos se manipularán con funciones públicas que aceptan punteros a los mismos, ocultando siempre los campos que los componen. Este punto, junto con el anterior de las interfaces, delimita perfectamente las barreras entre módulos, marcando claramente cuando acaba un problema y empieza otro.
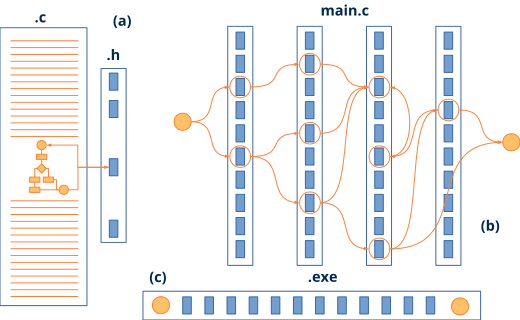
*.h suponen un gran nivel de abstracción ocultando la complejidad de la solución (a). Facilitan un desarrollo horizontal, basado en el problema, frente al aprendizaje vertical basado en APIs (b). Ayudan al enlazador a reducir el tamaño del ejecutable (c).Las dos primeras reglas ayudan a reducir la complejidad interna de un módulo haciéndolo lo mas legible y menos críptico posible. Podríamos enriquecerlas con otras sobre indentación, estilo, nombrado de variables, etc. Nosotros seguimos con mas o menos rigor los consejos del genial libro The Practice of Programming (Figura 5).

2.2. Avisos del compilador
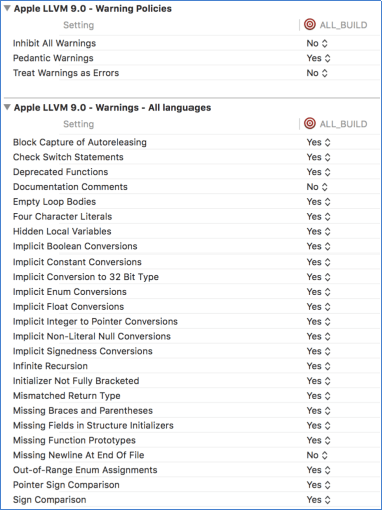
El compilador es nuestro gran aliado a la hora de examinar el código en busca de posibles fallos (Figura 6). Activar el mayor nivel posible de warnings es esencial para reducir errores derivados de la conversión de tipos, variables sin inicializar, código no alcanzable, etc. Todos los proyectos creados con NAppGUI se activará el mayor nivel de avisos posible, equivalente a -Wall -Wpedantic en todas las plataformas (Figura 7).
3. Análisis dinámico
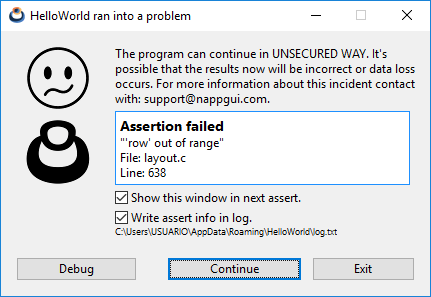
El análisis dinámico se realiza una vez el programa está en ejecución. Aquí nuestra principal arma son las auto-validaciones, implementadas como sentencias Asserts. Los asserts son comprobaciones distribuidas a lo largo y ancho del código fuente, que son evaluadas en tiempo de ejecución cada vez que el programa pasa por ellas. Si una sentencia se resuelve como FALSE, el proceso se parará y se mostrará una ventana informativa (Figura 8).
1 2 3 4 5 6 |
void layout_set_row_margin(Layout *layout, const uint32_t row, const real32_t margin) { cassert_no_null(layout); cassert_msg(row < layout->num_rows, "'row' out of range"); ... } |
Es posible también redirigir las sentencias assert a la salida estándar o al fichero de Log.
3.1. Deshabilitar Asserts
Dentro del código del SDK de NAppGUI se hayan repartidas más de 5000 sentencias asserts, localizadas en puntos estratégicos, que constantemente evalúan la coherencia e integridad del software. Evidentemente, este número irá creciendo tras cada revisión, a medida que vaya integrándose mayor funcionalidad. Esto convierte al SDK en un auténtico campo de minas, donde cualquier error en el uso de las funciones del API será automáticamente notificado al programador. Dependiendo de la configuración que estemos utilizando, los asserts serán activados o desactivados:
Debug: Las sentencias assert están activadas.Release: Las sentencias assert están desactivadas.ReleaseWithDebInfo: Como su nombre indica, activa todas los optimizaciones de Release, pero deja activadas las sentencias assert.
3.2. Depurando el programa
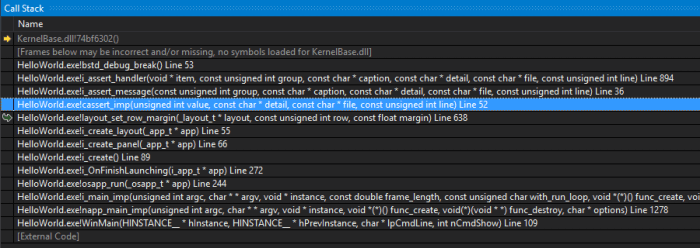
Cuando se activa un assert, el programa se detiene justo en el punto de la comprobación, mostrando la ventana de confirmación del assert. Si presionamos el botón [Debug], accederemos al call stack (Figura 9), que es la actual pila de llamadas a función, desde el propio main() hasta el punto de parada actual Segmento Stack. Navegando por la pila podemos chequear los valores de variables y objetos en cualquier nivel de llamada. Esto nos ayudará a identificar el origen del error, ya que la causa puede estar algunos niveles por debajo de la detección.
3.3. Registro de fallos
Un Log de ejecución es un archivo donde el programa va volcando información acerca de su estado o anomalías detectadas. Puede ser muy útil para conocer la causa de un fallo cuando el software ya ha sido distribuido y no es posible depurarlo. NAppGUI automáticamente crea un archivo de log para cada aplicación ubicado en el directorio de datos de la aplicación APP_DATA\APP_NAME\log.txt, por ejemplo C:\Users\USUARIO\AppData\Roaming\HelloWorld\log.txt.
1 2 3 4 5 |
[15:42:29] Starting log for 'HelloWorld' [15:42:29] TextView created: [0x6FFC7A30] [15:42:32] Assertion failed (c:\\nappgui_1_0\\src\\gui\\layout.c:638): "'row' out of range" [15:42:32] Assertion failed (c:\\nappgui_1_0\\src\\core\\array.c:512): "Array invalid index" [15:42:34] You have an execution log in: 'C:\\Users\\USUARIO\\AppData\\Roaming\\HelloWorld\\log.txt' |
Como puedes ver, los asserts se redirigen automáticamente al archivo log. Es posible deshabilitar esta escritura desmarcando el check 'Write assert info in log' de la ventana de información. También puedes añadir tus propios mensajes utilizando el método log_printf.
1 |
log_printf("TextView created: [0x%X]", view);
|
3.4. Auditor de memoria
El gestor de memoria de NAppGUI Heap, tiene asociado un auditor que comprueba que no haya fugas de memoria (leaks) tras cada ejecución de cada aplicación que utilice el SDK. Esto supone una gran ventaja con respecto al uso de utilidades externas, ya que las comprobaciones de memoria dinámica se están llevando a cabo siempre y no en fases aisladas del desarrollo.
1 2 3 4 5 6 7 8 9 10 11 |
[18:57:33] [OK] Heap Memory Staticstics [18:57:33] ============================ [18:57:33] Total a/dellocations: 652962, 652962 [18:57:33] Total bytes a/dellocated: 18085221250, 18085221250 [18:57:33] Max bytes allocated: 238229150 [18:57:33] Effective reallocations: (0/1169761) [18:57:33] Real allocations: 32776 pages of 65536 bytes [18:57:33] 13271 pages greater than 65536 bytes [18:57:33] ============================ [18:57:33] Config: Debug [18:57:33] You have an execution log in: 'C:\Users\USUARIO\AppData\Roaming\EuroPlane\log.txt'code. |