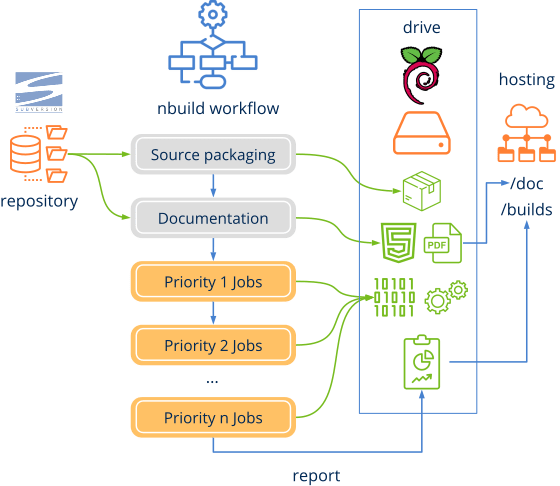
Flujos de trabajo
nbuild, ejecuta un flujo de trabajo fijo (Figura 1), donde existen ciertos pasos obligatorios y otros opcionales. Eso se configura mediante el segundo parámetro del comando nbuild -w workflow.json (Listado 1).

workflow.json.
1 2 3 4 5 6 7 8 9 10 11 |
{
"global" : { ... },
"repo" : { ... },
"doc" : { ... },
"hosting" : { ... },
"version" : "prj/version.txt",
"build" : "prj/build.txt",
"sources" : { ... },
"tests" : { ... },
"jobs" : { ... }
}
|
1. Globals
Esta sección del workflow.json contiene los datos principales del proyecto y del flujo:
1 2 3 4 5 6 7 8 9 10 |
"globals" : {
"project" : "NAppGUI",
"description" : "Cross-platform C SDK",
"start_year" : 2015,
"author" : "Francisco Garcia Collado",
"flowid" : "nappgui_src",
"license" : [
"MIT Licence",
"https://nappgui.com/en/legal/license.html" ],
}
|
flowid servirá para crear la estructura de directorios en drive y host que albergarán los artefactos y archivos temporales de este flujo concreto. El resto se utilizarán para tareas de registro y documentación. Por ejemplo, al añadir la información legal en cada archivo de código fuente.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
/* * NAppGUI Cross-platform C SDK * 2015-2026 Francisco Garcia Collado * MIT Licence * https://nappgui.com/en/legal/license.html * * File: stream.h * https://nappgui.com/en/core/stream.html * */ /* Data streams */ #include "core.hxx" |
2. Repositorio
Sección imprescindible que indica el acceso al repositorio donde está alojado el código (Listado 3).
1 2 3 4 5 |
"repo" : {
"url" : "svn://192.168.1.2/svn/NAPPGUI/trunk",
"user" : "user",
"pass" : "pass"
}
|
Inicialmente, solo se incluye soporte para repositorios Subversion. Está previsto añadir Git y sistemas de archivos locales.
3. Código fuente
No todo el código alojado en el repositorio puede ser necesario para el flujo que nos ocupa (Listado 4) (Figura 2). Dicho repositorio puede contener código de otros proyectos o archivos innecesarios, por lo que hay que realizar una selección y un empaquetado previo. El primer paso será generar un src.vers.tar.gz con el código relevante para el flujo. Este paquete se enviará a los compiladores a través de la red de nodos.
1 2 3 4 5 6 7 8 9 10 11 12 |
"sources" : [
{"name" : "src/sewer", "legal" : true, "analyzer" : true },
{"name" : "src/osbs", "legal" : true, "analyzer" : true },
{"name" : "src/core", "legal" : true, "analyzer" : true },
{"name" : "src/geom2d", "legal" : true, "analyzer" : true },
{"name" : "src/draw2d", "legal" : true, "analyzer" : true },
{"name" : "prj", "format" : false },
{"name" : "cicd/nappgui_src/CMakeTargets.cmake", "dest" : "CMakeTargets.cmake" },
...
{"name" : "CMakeLists.txt" },
{"name" : ".clang-format" }
]
|
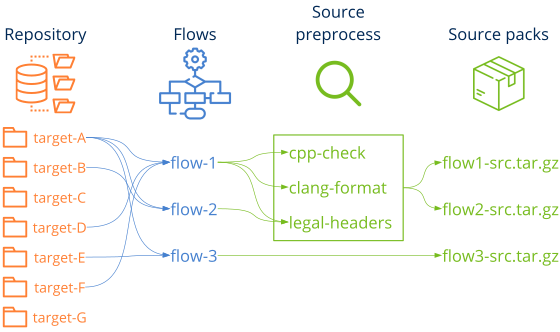
name: Nombre del directorio en el repositorio.dest: Nombre del directorio en el paquete (opcional).legal: Sitrue, se añadirá una cabecera con la información legal del proyecto en cada archivo de código fuente detectado (*.c, *.h, *.cpp, etc).format: Sitruey existe un.clang-format, se dará formato a los archivos de código fuente (*.c, *.h, *.cpp, etc).analyzer: Sitrue, se correrá un analizador de código estático para cada archivo de código fuente.
Importante:
- El paquete de código a compilar es un subconjunto del repositorio.
- Ningún nodo de la red (runner) tendrá acceso al repositorio, solo el nodo master.
- El código se empaqueta en un archivo
src.vers.tar.gzy se almacenará en drive, como un artefacto más. - El proceso de empaquetado realiza un "preproceso" de los archivos, tal como darles formato, incluir información legal o correr analizadores estáticos.
- El paquete generado debe disponer de un
CMakeLists.txtque permita compilar el código e instalar los binarios y cabeceras.
4. Código de test
Es un proceso opcional similar al empaquetado de código fuente, se generará el paquete de test en test.vers.tar.gz (Listado 5). Si no se especifican tests, el flujo tan solo compilará el código, pero no lo comprobará.
exec: Comando ejecutable para lanzar el test.
1 2 3 4 5 6 7 8 9 10 11 12 13 |
"tests" : [
{"name" : "test/tlib", "dest" : "tlib" },
{"name" : "test/data", "dest" : "data" },
{"name" : "test/dylib", "dest" : "dylib" },
{"name" : "test/sewer", "dest" : "sewer", "exec" : "sewer_test" },
{"name" : "test/osbs", "dest" : "osbs", "exec" : "osbs_test" },
{"name" : "test/core", "dest" : "core", "exec" : "core_test" },
{"name" : "test/draw2d", "dest" : "draw2d", "exec" : "draw2d_test" },
{"name" : "test/encode", "dest" : "encode" , "exec" : "encode_test"},
{"name" : "test/inet", "dest" : "inet" , "exec" : "inet_test"},
{"name" : "test/CMakeLists.txt", "dest" : "CMakeLists.txt" }
],
]
|
5. Documentación
De forma opcional, el flujo permite generar la documentación del proyecto, utilizando ndoc (Listado 6). Esta herramienta forma parte del proyecto nbuild y permite generar sitios web estáticos en diferentes idiomas, así como ebooks en PDF, basados en el compositor de textos LaTeX.
1 2 3 4 5 |
"doc" : {
"url" : "svn://192.168.1.2/svn/NAPPGUI/trunk/doc",
"user" : "user",
"pass" : "pass"
}
|
Ejemplos generados con ndoc, los tenemos es:
6. Hosting
De forma también opcional, nbuild puede publicar, tanto la documentación del proyecto como los informes de compilación en un servidor web externo. Este permitirá tener acceso a cualquier tipo de informe desde cualquier lugar, fuera de la red interna de desarrollo.
1 2 3 4 5 6 7 |
"hosting" : {
"url" : "hosting_url",
"user" : "user",
"pass" : "pass",
"docpath" : "./web/docs",
"buildpath" : "./web/builds"
}
|
7. Trabajos de compilación
Y, por último, lo más importante. Debemos de indicar los trabajos de compilación que deseamos ejecutar dentro de este flujo (Listado 8).
1 2 3 4 5 6 7 |
"jobs": [
{"priority" : 1, "name" : "ub24_clang_x64_deb", "config" : "Debug", "tags" : ["ubuntu24", "x64"], "generator" : "Ninja", "opts" : "-DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++" },
{"priority" : 1, "name" : "ub24_gcc_x64_dll_rel", "config" : "Release", "tags" : ["ubuntu24", "x64"], "generator" : "Unix Makefiles", "opts" : "-DCMAKE_C_COMPILER=gcc -DCMAKE_CXX_COMPILER=g++ -DNAPPGUI_SHARED=YES" },
{"priority" : 1, "name" : "ub24_gcc_x64_rel", "config" : "Release", "tags" : ["ubuntu24", "x64"], "generator" : "Ninja", "opts" : "-DCMAKE_C_COMPILER=gcc -DCMAKE_CXX_COMPILER=g++" },
{"priority" : 1, "name" : "ub24_clang_x64_dll_deb", "config" : "Debug", "tags" : ["ubuntu24", "x64"], "generator" : "Unix Makefiles", "opts" : "-DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DNAPPGUI_SHARED=YES" },
...
]
|
priority: Si tenemos muchas tareas, es posible dividirlas en grupos con prioridad creciente. En cada ejecución, nbuild solo compilará aquellas tareas de mayor prioridad (menor valor).name: Nombre de la tarea, para mostrar en registros e informes.config: Configuración (Debug,Release, etc).tags: Etiquetas necesarias para seleccionar un runner correcto para la compilación.generator: Generador CMake con el que deseamos configurar la compilación.opts: Opciones adicionales de CMake necesarias para configurar la compilación.
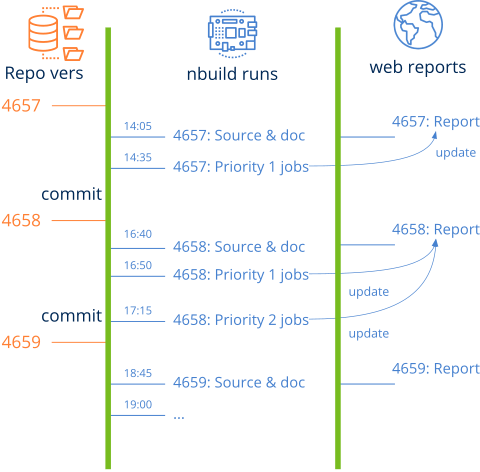
El flujo ha sido diseñado para completar las tareas de mayor prioridad lo más rápido posible, por lo que ejecuciones sucesivas de nbuild irán completando aquellos trabajos de menor prioridad (Figura 3). En momentos donde el código cambie con frecuencia, nbuild se centrará en aquellas tareas de máxima prioridad. Con esto pretendemos detectar lo antes posible cualquier error introducido en los últimos cambios. Por el contrario, en etapas de baja actividad (noches o fines de semana), el sistema irá completando paulatinamente las tareas de baja prioridad, hasta cubrir todo el espectro de compilaciones y pruebas existentes en workflow.json.
Se pueden lanzar diferentes instancias de nbuild en paralelo, siempre que trabajen sobre flujos diferentes.
8. Datos adicionales
Estas entradas son opcionales dentro del workflow.json pero se recomienda incluirlas.
version: Archivo dentro del repositorio que indica la versión del software. Tan solo debe incluir una línea con el formatomajor.minor.path(1.5.6).build: Ruta dentro del empaquetado final que contendrá información sobre el paquete compilado.
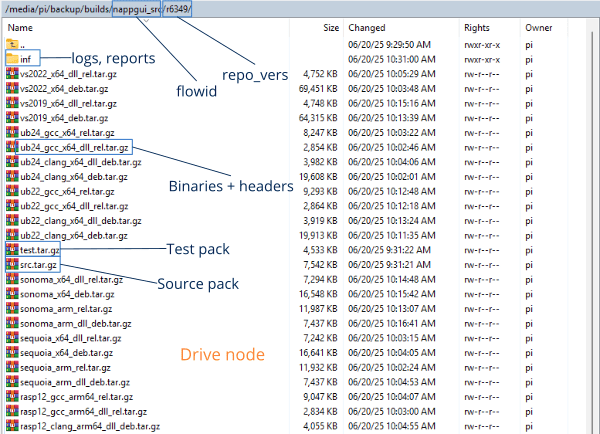
9. Gestión de artefactos en drive
Como ya hemos indicado en secciones anteriores, todos los paquetes, binarios, reportes y informes se almacenan en un nodo concreto de la red, denominado drive, dotado de gran capacidad de disco (Figura 4). La información se organiza por el nombre del flujo y versión del repositorio (Figura 5).