


Unicode
Funciones
| uint32_t | unicode_convers (...) |
| uint32_t | unicode_convers_n (...) |
| uint32_t | unicode_convers_nbytes (...) |
| uint32_t | unicode_nbytes (...) |
| uint32_t | unicode_nchars (...) |
| uint32_t | unicode_to_u32 (...) |
| uint32_t | unicode_to_u32b (...) |
| uint32_t | unicode_to_char (...) |
| bool_t | unicode_valid_str (...) |
| bool_t | unicode_valid_str_n (...) |
| bool_t | unicode_valid (...) |
| const char_t* | unicode_next (...) |
| const char_t* | unicode_back (...) |
| bool_t | unicode_isascii (...) |
| bool_t | unicode_isalnum (...) |
| bool_t | unicode_isalpha (...) |
| bool_t | unicode_iscntrl (...) |
| bool_t | unicode_isdigit (...) |
| bool_t | unicode_isgraph (...) |
| bool_t | unicode_isprint (...) |
| bool_t | unicode_ispunct (...) |
| bool_t | unicode_isspace (...) |
| bool_t | unicode_isxdigit (...) |
| bool_t | unicode_islower (...) |
| bool_t | unicode_isupper (...) |
| uint32_t | unicode_tolower (...) |
| uint32_t | unicode_toupper (...) |
Unicode es un estándar de la industria informática, en esencia una tabla, que asigna un número único a cada símbolo de cada idioma en el mundo (Figura 1). Estos valores generalmente se denominan codepoints y se representan escribiendo U+ seguido de su número en hexadecimal.
- Utiliza unicode_convers para convertir una cadena de una codificación a otra.
- Utiliza unicode_to_u32 para obtener el primer codepoint de una cadena.

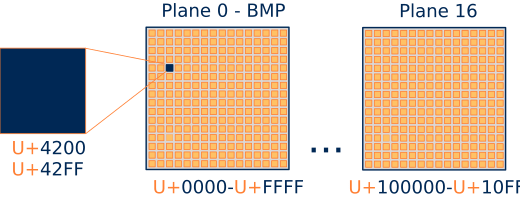
Hablando de su estructura, tiene 17 planos de 65536 codepoints cada uno (256 bloques de 256 elementos) (Figura 2). Esto le da a Unicode un límite teórico de 1114112 caracteres, de los cuales 136755 ya se han ocupado (versión 10.0 de junio de 2017). Para aplicaciones del mundo real, el más importante es el Plano 0 denominado Plano Multilingüe Básico (BMP), que incluye los símbolos de todas las idiomas modernos del mundo. Los planos superiores contienen carácteres históricos y símbolos adicionales poco convencionales.
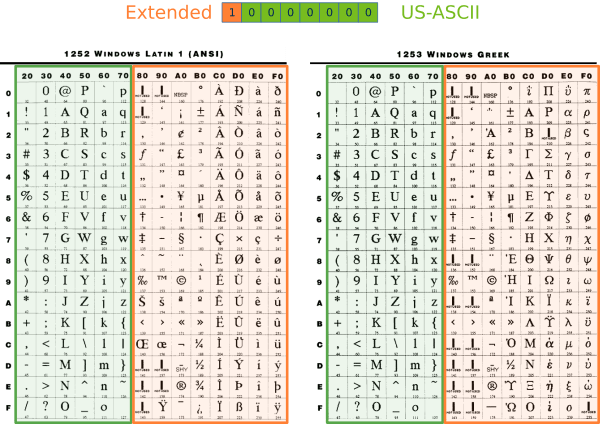
Las primeros computadores utilizaban ASCII American Standard Code for Information Interchange, un código de 7 bits que define todos los caracteres del idioma Inglés: 26 letras minúsculas (sin signos diacríticos), 26 letras mayúsculas, 10 dígitos, 32 símbolos de puntuación, 33 códigos de control y un espacio en blanco, para un total de 128 posiciones. Tomando el bit adicional dentro de un byte, tendremos espacio para otros 128 símbolos, pero aún insuficiente para todos. Esto da como resultado numerosas páginas de códigos ASCII extendidos, lo que es un gran problema para compartir textos, ya que el mismo código numérico puede representar diferentes símbolos según la página ASCII utilizada (Figura 3).
Ya a principios de los 90, con la llegada de Internet, este problema se agravó, ya que el intercambio de información entre máquinas de diferente naturaleza y país se convirtió en algo cotidiano. El Consorcio de Unicode (Figura 4) se contituyó en California en enero de 1991 y, en octubre del mismo año, se publicó el primer volumen del estándar Unicode.

1. Codificaciones UTF
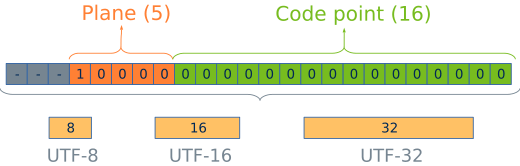
Cada codepoint necesita 21 bits para ser representado (5 para el plano y 16 para el desplazamiento). Esto casa muy mal con los tipos básicos en ordenadores (8, 16 o 32 bits). Por este motivo, se han definido tres codificaciones Unicode Translation Format - UTF función del tipo de dato que se utilice en la representación (Figura 5).
1.1. UTF-32
Sin ningún problema, utilizando 32 bits podemos almacenar cualquier codepoint. También podemos acceder aleatoriamente mediante un índice a los elementos de un array, de la misma forma que las cadenas ASCII clásicas de C (char). Las malas noticias son los requisitos de memoria. Una cadena UTF32 necesita cuatro veces más espacio que una ASCII.
1 2 3 4 5 6 7 8 9 |
1.2. UTF-16
UTF16 reduce a la mitad el espacio requerido por UTF32. Es posible almacenar un codepoint por elemento siempre que no abandonemos el plano 0 (BMP). Para planos superiores, serán necesarios dos elementos UTF16 (32bits). Este mecanismo, que encapsula los planos superiores dentro del BMP, se conoce como pares subrogados.
1 2 3 4 5 6 7 8 9 |
Para iterar sobre una cadena UTF16 que contenga caracteres de cualquier plano debe utilizarse unicode_next.
1.3. UTF-8
UTF8 es un código de longitud variable donde cada codepoint utiliza 1, 2, 3 o 4 bytes.
- 1 byte (0-7F): los 128 símbolos del ASCII original. Esto supone una gran ventaja, ya que las cadenas US-ASCII son cadenas UTF8 válidas, sin necesidad de conversión.
- 2 bytes (80-7FF): Caracteres diacríticos y de lenguaje romance, griego, cirílico, coptos, armenio, hebreo, árabe, siríaco y thaana, entre otros. Un total de 1920 codepoints.
- 3 bytes (800-FFFF): Resto del plano 0 (BMP).
- 4 bytes (10000-10FFFF): Planos superiores (1-16).

Más del 90% de los sitios web utilizan UTF8 (agosto de 2018), porque es el más óptimo en términos de memoria y velocidad de transmisión en red. Como desventaja, tiene asociado un pequeño coste computacional para codificar/decodificar, ya que es necesario realizar operaciones de nivel de bit para obtener los codepoints. Tampoco es posible acceder aleatoriamente mediante índice a un carácter concreto, tenemos que procesar la cadena completa.
1 2 3 4 5 6 7 8 9 10 11 |
const char_t code1[] = "Hello"; const char_t code2[] = "áéíóú"; const char_t *iter = code1; uint32_t s1 = sizeof(code1); /* s1 == 6 */ uint32_t s2 = sizeof(code2); /* s2 == 11 */ for (i = 0; i < 5; ++i) { if (unicode_to_u32(iter, ekUTF8) == 'H') return i; iter = unicode_next(iter, ekUTF8); } |
1.4. Uso de UTF-8
UTF8 es la codificación requerida por todas las funciones del SDK NAppGUI. Las razones por las que hemos elegido UTF-8 sobre otras codificaciones han sido:
- Es la evolución natural del US-ASCII.
- Las aplicaciones serán directamente compatibles con la gran mayoría de servicios de Internet (JSON/XML).
- En entornos multi-lenguaje los textos ocuparán menos espacio. Estadísticamente, los 128 caracteres ASCII son los más utilizados en promedio y solo necesitan un byte en UTF8.
- Como desventaja, en aplicaciones dirigidas exclusivamente al mercado asiático (China, Japón, Corea - CJK), UTF8 es menos eficiente que UTF16.
Dentro de aplicaciones NAppGUI pueden cohexistir diferentes representaciones (char16_t, char32_t, wchar_t). No obstante, recomendamos encarecidamente el uso de UTF8 en favor de la portabilidad y para evitar las constantes conversiones dentro del API. Para convertir cualquier cadena a UTF8 se utiliza la función unicode_convers.
1 2 3 |
wchar_t text[] = L"My label text."; char_t ctext[128]; unicode_convers((const char_t*)text, ctext, ekUTF16, ekUTF8, 128); |
NAppGUI no ofrece soporte para convertir páginas del ASCII Extendido a Unicode.
El objeto Stream proporciona conversiones automáticas de UTF al leer o escribir en canales de E/S mediante los métodos stm_set_write_utf y stm_set_read_utf. También es posible trabajar con el tipo String (cadenas dinámicas), que incorpora multitud de funciones optimizadas para el tratamiento UTF8. Podemos incluir cadenas de texto constantes directamente en el código fuente (Figura 7), aunque lo habitual será escribirlas en archivos de recursos (Recursos). Evidentemente, deberemos guardar tanto los archivos de código fuente como los de recursos en UTF8. Todos los entornos de desarrollo actuales soportan la opción:
- De forma predeterminada, Visual Studio guarda los archivos fuente en formato ASCII (Windows 1252). Para cambiar a UTF8, ir a
File->Save As->Save with encoding-> Unicode (UTF8 Without Signature) - Codepage 65001. No hay forma de establecer esta configuración para todo el proyecto :-(. - En Xcode es posible establecer una configuración global.
Preferences->Text editing->Default Text Encoding->Unicode (UTF-8). - En Eclipse también permite una configuración global.
Window->Preferences->General->Workspace->Text file encoding.
unicode_convers ()
Convierte una cadena Unicode de una codificación a otra.
uint32_t unicode_convers(const char_t *from_str, char_t *to_str, const unicode_t from, const unicode_t to, const uint32_t osize);
1 2 3 |
const char32_t str[] = U"Hello World"; char_t utf8_str[256]; unicode_convers((const char_t*)str, utf8_str, ekUTF32, ekUTF8, 256); |
| from_str | Cadena de origen (terminada en carácter nulo '\0'). |
| to_str | Buffer de destino. |
| from | Codificación de cadena origen. |
| to | Codificación requerida en |
| osize | Tamaño del búfer de salida. Número máximo de bytes que se escribirán en |
Retorna
Número de bytes escritos en to_str (incluido el carácter nulo).
unicode_convers_n ()
Igual que unicode_convers, pero indicando un tamaño máximo para la cadena de entrada.
uint32_t unicode_convers_n(const char_t *from_str, char_t *to_str, const unicode_t from, const unicode_t to, const uint32_t isize, const uint32_t osize);
| from_str | Cadena de origen. |
| to_str | Buffer de destino. |
| from | Codificación de cadena origen. |
| to | Codificación requerida en |
| isize | Tamaño de la cadena en entrada (en bytes). |
| osize | Tamaño del búfer de salida. |
Retorna
Número de bytes escritos en to_str.
unicode_convers_nbytes ()
Calcula el número de bytes necesarios para convertir una cadena Unicode de una codificación a otra. Será útil calcular el espacio necesario en reserva dinámica de memoria.
uint32_t unicode_convers_nbytes(const char_t *str, const unicode_t from, const unicode_t to);
1 2 3 |
const char32_t str[] = U"Hello World"; uint32_t size = unicode_convers_nbytes((char_t*)str, ekUTF32, ekUTF8); / * size == 12 * / |
| str | Cadena de origen (terminada en nulo). |
| from | Codificación de |
| to | Codificación requerida. |
Retorna
Número de bytes necesarios (incluido el carácter nulo).
unicode_nbytes ()
Obtiene el tamaño (en bytes) de una cadena Unicode.
uint32_t unicode_nbytes(const char_t *str, const unicode_t format);
| str | Cadena Unicode (terminada en '\0'). |
| format | Codificación de |
Retorna
El tamaño en bytes ('\0' incluido).
unicode_nchars ()
Calcula la longitud (en caracteres) de una cadena Unicode.
uint32_t unicode_nchars(const char_t *str, const unicode_t format);
| str | Cadena Unicode (terminada en '\0'). |
| format | Codificación de |
Retorna
El número de caracteres ('\0' no incluido).
Observaciones
En cadenas ASCII, el número de bytes es igual al número de caracteres. En Unicode depende de la codificación y la cadena.
unicode_to_u32 ()
Obtiene el valor del primer codepoint de la cadena Unicode.
uint32_t unicode_to_u32(const char_t *str, const unicode_t format);
1 2 3 |
char_t str[] = "áéíóúÄÑ£"; uint32_t cp = unicode_to_u32(str, ekUTF8); /* cp == 'á' == 225 == U+E1 */ |
| str | Cadena Unicode (terminada en '\0'). |
| format | Codificación de |
Retorna
El código del primer carácter de str.
unicode_to_u32b ()
Igual que unicode_to_u32 pero con con campo adicional para almacenar la cantidad de bytes que ocupa el codepoint.
uint32_t unicode_to_u32b(const char_t *str, const unicode_t format, uint32_t *bytes);
| str | Cadena Unicode (terminada en '\0'). |
| format | Codificación de |
| bytes | Guarda el número de bytes necesarios para representar el codepoint mediante |
Retorna
El código del primer carácter de str.
unicode_to_char ()
Escribe el codepoint al comienzo de str, utilizando la codificación format.
uint32_t unicode_to_char(const uint32_t codepoint, char_t *str, const unicode_t format);
1 2 3 4 5 |
char_t str[64] = \"\";
uint32_t n = unicode_to_char(0xE1, str, ekUTF8);
unicode_to_char(0, str + n, ekUTF8);
/* str == "á" */
/* n = 2 */
|
| codepoint | Código del carácter. |
| str | Cadena de destino. |
| format | Codificación para |
Retorna
El número de bytes escritos (1, 2, 3 or 4).
Observaciones
Para escribir varios codepoints, combinar unicode_to_char con unicode_next.
unicode_valid_str ()
Comprueba si una cadena es Unicode.
bool_t unicode_valid_str(const char_t *str, const unicode_t format);
| str | Cadena a comprobar (terminada en '\0'). |
| format | Codificación Unicode esperada. |
Retorna
TRUE si es válida.
unicode_valid_str_n ()
Igual que unicode_valid_str, pero indicando un tamaño máximo para la cadena de entrada.
bool_t unicode_valid_str_n(const char_t *str, const uint32_t size, const unicode_t format);
| str | Cadena a comprobar. |
| size | Máximo tamaño de la cadena (en bytes). |
| format | Codificación Unicode esperada. |
Retorna
TRUE si es válida.
unicode_valid ()
Comprueba si un codepoint es válido.
bool_t unicode_valid(const uint32_t codepoint);
| codepoint | El código Unicode del carácter. |
Retorna
TRUE si el parámetro es un codepoint válido. De lo contrario, FALSE.
unicode_next ()
Avanza al siguiente carácter de una cadena Unicode. En general no es posible el acceso aleatorio como hacemos en ANSI-C (str[i++]). Debemos iterar una cadena desde el principio. Ver Codificaciones UTF.
const char_t* unicode_next(const char_t *str, const unicode_t format);
1 2 3 4 5 6 7 8 9 |
char_t str[] = "áéíóúÄ"; char_t *iter = str; /* iter == "áéíóúÄ" */ iter = unicode_next(iter, ekUTF8); /* iter == "éíóúÄ" */ iter = unicode_next(iter, ekUTF8); /* iter == "íóúÄ" */ iter = unicode_next(iter, ekUTF8); /* iter == "óúÄ" */ iter = unicode_next(iter, ekUTF8); /* iter == "úÄ" */ iter = unicode_next(iter, ekUTF8); /* iter == "Ä" */ iter = unicode_next(iter, ekUTF8); /* iter == "" */ iter = unicode_next(iter, ekUTF8); /* Segmentation fault!! */ |
| str | Cadena Unicode. |
| format | Codificación de |
Retorna
Puntero al siguiente carácter de la cadena.
Observaciones
No verifica el final de la cadena. Debemos detener la iteración cuando codepoint == 0.
unicode_back ()
Retrocede al carácter anterior de una cadena Unicode.
const char_t* unicode_back(const char_t *str, const unicode_t format);
| str | Cadena Unicode. |
| format | Codificación de |
Retorna
Puntero al carácter anterior de la cadena.
Observaciones
No verifica el inicio de la cadena.
unicode_isascii ()
Comprueba si codepoint es un carácter US-ASCII 7.
bool_t unicode_isascii(const uint32_t codepoint);
| codepoint | El código Unicode del carácter. |
Retorna
Resultado del test.
unicode_isalnum ()
Comprueba si codepoint es un carácter alfanumérico.
bool_t unicode_isalnum(const uint32_t codepoint);
| codepoint | El código Unicode del carácter. |
Retorna
Resultado del test.
Observaciones
Solo tiene en cuenta caracteres US-ASCII.
unicode_isalpha ()
Comprueba si codepoint es un carácter alfabético.
bool_t unicode_isalpha(const uint32_t codepoint);
| codepoint | El código Unicode del carácter. |
Retorna
Resultado del test.
Observaciones
Solo tiene en cuenta caracteres US-ASCII.
unicode_iscntrl ()
Comprueba si codepoint es un carácter de control.
bool_t unicode_iscntrl(const uint32_t codepoint);
| codepoint | El código Unicode del carácter. |
Retorna
Resultado del test.
Observaciones
Solo tiene en cuenta caracteres US-ASCII.
unicode_isdigit ()
Comprueba si codepoint es dígito (0-9).
bool_t unicode_isdigit(const uint32_t codepoint);
| codepoint | El código Unicode del carácter. |
Retorna
Resultado del test.
Observaciones
Solo tiene en cuenta caracteres US-ASCII.
unicode_isgraph ()
Comprueba si codepoint es un carácter imprimible (excepto el espacio blanco ' ').
bool_t unicode_isgraph(const uint32_t codepoint);
| codepoint | El código Unicode del carácter. |
Retorna
Resultado del test.
Observaciones
Solo tiene en cuenta caracteres US-ASCII.
unicode_isprint ()
Comprueba si codepoint es un carácter imprimible (incluido el espacio blanco ' ').
bool_t unicode_isprint(const uint32_t codepoint);
| codepoint | El código Unicode del carácter. |
Retorna
Resultado del test.
Observaciones
Solo tiene en cuenta caracteres US-ASCII.
unicode_ispunct ()
Comprueba si codepoint es un carácter imprimible (expecto el espacio blanco ' ' y alfanuméricos).
bool_t unicode_ispunct(const uint32_t codepoint);
| codepoint | El código Unicode del carácter. |
Retorna
Resultado del test.
Observaciones
Solo tiene en cuenta caracteres US-ASCII.
unicode_isspace ()
Comprueba si codepoint es un carácter de espaciado, nueva línea, retorno de carro, tabulador horizontal o vertical.
bool_t unicode_isspace(const uint32_t codepoint);
| codepoint | El código Unicode del carácter. |
Retorna
Resultado del test.
Observaciones
Solo tiene en cuenta caracteres US-ASCII.
unicode_isxdigit ()
Comprueba si codepoint es un dígito hexadecimal 0 1 2 3 4 5 6 7 8 9 a b c d e f A B C D E F.
bool_t unicode_isxdigit(const uint32_t codepoint);
| codepoint | El código Unicode del carácter. |
Retorna
Resultado del test.
Observaciones
Solo tiene en cuenta caracteres US-ASCII.
unicode_islower ()
Comprueba si codepoint es una letra minúscula.
bool_t unicode_islower(const uint32_t codepoint);
| codepoint | El código Unicode del carácter. |
Retorna
Resultado del test.
Observaciones
Solo tiene en cuenta caracteres US-ASCII.
unicode_isupper ()
Comprueba si codepoint es una letra mayúscula.
bool_t unicode_isupper(const uint32_t codepoint);
| codepoint | El código Unicode del carácter. |
Retorna
Resultado del test.
Observaciones
Solo tiene en cuenta caracteres US-ASCII.
unicode_tolower ()
Convierte una letra a minúscula.
uint32_t unicode_tolower(const uint32_t codepoint);
| codepoint | El código Unicode del carácter. |
Retorna
La conversión a minúscula si la entrada es una letra mayúscula. De lo contrario, el mismo codepoint.
Observaciones
Solo tiene en cuenta caracteres US-ASCII.
unicode_toupper ()
Convierte una letra a mayúscula.
uint32_t unicode_toupper(const uint32_t codepoint);
| codepoint | El código Unicode del carácter. |
Retorna
La conversión a mayúscula si la entrada es una letra minúscula. De lo contrario, el mismo codepoint.
Observaciones
Solo tiene en cuenta caracteres US-ASCII.