


Expresiones regulares
Funciones
| RegEx* | regex_create (...) |
| void | regex_destroy (...) |
| bool_t | regex_match (...) |
Las expresiones regulares definen un patrón de texto que puede utilizarse para buscar o comparar cadenas (Listado 1).
- Utiliza regex_create para crear una expresión regular.
- Utiliza regex_match para comprobar si una cadena cumple con el patrón.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
RegEx *regex = regex_create(".*.txt"); const char_t *str[] = { "file01.txt", "image01.png", "sun01.jpg", "films.txt", "document.pdf"}; uint32_t i, n = sizeof(str) / sizeof(char_t*); for (i = 0; i < n; ++i) { if (regex_match(regex, str[i]) == TRUE) bstd_printf("YES: %s\n", str[i]); else bstd_printf("NO: %s\n", str[i]); } regex_destroy(®ex); |
1 2 3 4 5 |
YES: file01.txt NO: image01.png NO: sun01.jpg YES: films.txt NO: document.pdf |
1. Definir patrones
Podemos construir una expresión regular a partir de una cadena de texto, siguiendo estas sencillas reglas:
- Un patrón cadena se corresponde únicamente con esa misma cadena.
- Un punto
'.'equivale a "cualquier carácter". - Un guión
'A-Z'establece un rango de caracteres, utilizando el código Unicode de ambos extremos.
|
|
"hello" --> {"hello"}
|
|
|
"h.llo" --> {"hello", "htllo", "hällo", "h5llo", ...}
|
|
|
"A-Zello" --> {"Aello", "Bello", "Cello", ..., "Zello"}
'A-Z': (65-90) (ABCDEFGHIJKLMNOPQRSTUVWXYZ)
'0-9': (48-57) (0123456789)
'á-ú': (225-250) (áâãäåæçèéêëìíîïðñòóôõö÷øùú)
|
Al igual que los objetos String, los patrones se expresan en UTF-8, por tanto, puede utilizarse todo el conjunto Unicode para crear expresiones regulares.
- Los corchetes
'[áéíóú]'permiten alternar entre varios caracteres. - El asterisco
'*'permite que el último carácter aparezca cero o más veces. - Los paréntesis
'(he*llo)'permiten agrupar una expresión regular, de tal forma que se comporte como un único carácter. - Para que
'.', '-', '[]', '*', '()'sean interpretados como carácteres, utilizar el backslash'\'.
|
|
"h[áéíóú]llo" --> {"hállo", "héllo", "híllo", "hóllo", "húllo"}
|
|
|
"he*llo" --> {"hllo", "hello", "heello", "heeello", "heeeello", ...}
"h.*llo" --> {"hllo", "hello", "hallo", "hillo", "hasello", ...}
"hA-Z*llo" --> {"hllo", "hAllo", "hABllo", "hVFFRREASllo" }
--> {"hAQWEDllo", hAAABBRSllo", ...}
"FILE_0-9*.PNG" --> {"FILE_.PNG", "FILE_0.PNG", "FILE_01.PNG" }
--> {"FILE_456.PNG", "FILE_112230.PNG",...}
|
|
|
"[(hello)(bye)]" --> {"hello", "bye" }
"[(red)(blue)(1*)]" --> {"red", "blue", "", "1", "11", "111", ... }
"(hello)*" --> {"", "hello", "hellohello", "hellohellohello", ... }
"(he*llo)ZZ" --> {"hlloZZ", "helloZZ", "heelloZZ", "heeelloZZ", ... }
|
|
|
"\(he\*\-llo\)" --> {"(he*-llo)"}
|
Recuerda que para expresiones insertadas como constantes en código C, el carácter backslash se representa con doble barra "\\\\(he\\\\*\\\\-llo\\\\)".
2. Lenguajes regulares y autómatas
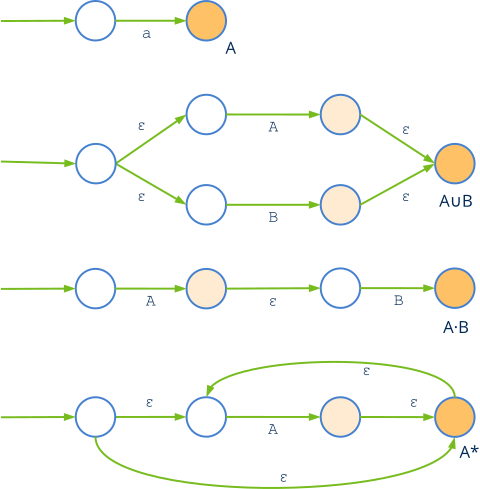
Los lenguajes regulares son aquellos que se definen de forma recursiva utilizando tres operaciones básicas sobre el conjunto de carácteres (o símbolos) disponibles. Se pueden describir mediante las expresiones regulares comentadas anteriormente.
- Cada carácter 'a' es un lenguaje regular 'A'.
- La unión de dos lenguajes regulares, es un lenguaje regular A∪B.
- La concatenación de dos lenguajes regulares, es un lenguaje regular A·B.
- La clausura de un lenguaje regular, es un lenguaje regular A*. Aquí es donde entra en juego la recursión.
En este contexto los símbolos son todos los carácteres Unicode. Pero pueden definirse lenguajes basados en otros alfabetos, incluido el binario {0, 1}.
Para reconocer si una cadena pertenece o no a un determinado lenguaje regular, es necesario construir un Autómata Finito basándonos en las reglas reflejadas en (Figura 1).
regex_create ()
Crea una expresión regular a partir de un patrón.
RegEx* regex_create(const char_t *pattern);
| pattern | Patrón de búsqueda. |
Retorna
Expresión regular (autómata).
Observaciones
Ver Definir patrones.
regex_destroy ()
Destruye una expresión regular.
void regex_destroy(RegEx **regex);
| regex | Expresión regular. Será puesto a |
regex_match ()
Comprueba si una cadena cumple el patrón de búsqueda.
bool_t regex_match(const RegEx *regex, const char_t *str);
| regex | Expresión regular. |
| str | Cadena a evaluar. |
Retorna
TRUE si la cadena es aceptada por la expresión regular.